A Day in the Life of a Data Scientist: What to Expect

In this article
Every IT job has an air of mystery to its roles and responsibilities. If you’re beginning a career in data science, you may be wondering what a day in the life of a data scientist looks like. There are several factors that influence the typical day for a data scientist – are you working for a start-up or a multinational company? Are you a full-time data scientist or an intern or a freelancer?
It is actually very difficult to describe a typical day in the life of a data scientist because when your day-to-day tasks involve building data products to solve problems for billions of people, it is not possible to have a “typical” day. Every day in the life of a data scientist is a new challenge. Finding out what a data scientist does isn’t a cakewalk. Yet, we will try to understand and decode what a typical day looks like in the life of a data scientist.
A Day in the Life of a Data Scientist – Decoded
- Defining the Data Science Problem
One of the most important and primary steps that every data scientist follows along the data science pipeline is to identify and define the business problem by asking a lot of right questions. Data is only as good as the questions you ask. Unless a data scientist asks the right questions, it cannot provide the right insights for better business decision-making. This involves various tasks such as understanding the business requirements, scoping an efficient solution, and planning the data analysis. Data scientists are responsible for analyzing the pain points of the stakeholders and framing a data science problem from a stakeholder’s perspective. They gain domain knowledge from stakeholders and combine it with the data and the technical knowledge to build a data product for better business gains.
- Gather Raw Data for Analysis of the Defined Problem
Having defined the business problem, a data scientist is responsible for collecting all the required data that will help them solve the business problem. The next important task in the data science pipeline is to identify the data sources they have to dig in to get all the relevant data, choose the required fields, and collate all relevant information in one place that might be required in the future. If the required data is already available with the organization, well and good. Otherwise, if a data scientist thinks that the available data is not enough to solve the business problem, they make arrangements to collect new data either through feedback from customers, surveys or by setting up a popular auto data collection paradigm like cookies for a website, etc. Once raw data is collected, a data scientist cleans and organizes the data(70% of a data scientist’s time is spent on this) to make corrections for any errors, remove missing values and identify duplicate records.
- Decide on an Approach to Solve the Data Science Problem
Having gathered all the data and understanding what questions they want to answer, a data scientist explores the best and most efficient methods to answer these questions. The best and most efficient might not always be the same and finding a trade-off solution is the responsibility of a data scientist. For instance, some of the questions can be answered by running a k- means clustering algorithm but this could be an expensive method particularly if it requires several iterations for a large dataset. However, these questions could also be answered with a simpler distance calculation method. A data scientist has to decide on the best method to approach a data science problem. There are various algorithmic approaches that can be applied to a data science problem, a few of them are listed below–
- Two-Class Classification Approach – works best for finding answers to questions that have only two possible answers.
- Multi-Class Classification Approach – works best for finding answers to questions that have multiple possible answers.
- Reinforcement Learning Algorithms – when your problem is not predictive in nature and requires you to figure out what are good actions.
- Regression – works best for questions that have a real-valued answer instead of a class or a category.
- Clustering – works best when you want to classify each data point into a specific group and answer questions about how data is organized.
- Perform in-depth Data Analysis – Apply Statistical Modelling, Algorithms, and Machine Learning
The data that comes from 2.1 billion mobile devices, 216 million computers that were sold last year, or let’s say 1 million tablets need to be analyzed to glean meaningful insights. A data scientist is responsible for building automated machine learning pipelines and personalized data products for profitable business decision-making. Having explored the data and decided on an approach, a data scientist analyses the data to get valuable information from it. There are several open-source data science tools and libraries in Python and R that can be used to analyze data and glean high-value insights for better business decision-making. There are chances that an approach decided on in the above Step 3 might not work when a data scientist actually begins to analyze the data. A data scientist then has to start trying other machine learning approaches and see what works best for their data science problem using the following 5-step approach –
- Build a machine learning model to answer the questions.
- Validate the model built against the data collected.
- Apply necessary algorithms and perform statistical analysis
- Present the results using various data visualization tools.
- Compare the results with other approaches.
A data scientist experiments with several models and approaches before finding the best solution for a data science problem.
- Communicate Insights to the Stakeholders
Having tweaked and optimized the model to obtain the best results, the next most important task of a data scientist is to effectively communicate the findings so various stakeholders can understand the insights and take further action based on them. A picture is worth a million datasets. Data scientists work with various data visualization tools like Tableau, QlikView, Matplotlib, ggplot, and others to demonstrate real-life cases on how the model is working on the actual customer. They create presentations with an appropriate flow to narrate a story the data can tell in a way that is easily comprehensible and compelling to the stakeholders.
Related Read: Data Scientist Job Description
Get To Know Other Data Science Students

Bret Marshall
Software Engineer at Growers Edge

Diana Xie
Machine Learning Engineer at IQVIA

Jasmine Kyung
Senior Operations Engineer at Raytheon Technologies
Meet Charlie Brown – Our Superhero Data Scientist
Charlie Brown is the name of our mental framework for an exemplary data scientist. Charlie has messy hair, wears round glasses, has intellectual curiosity, and has a proactive problem-solving attitude. Charlie is the fictional character that we will use as a thinking model in this blog post to understand what a data scientist does on a day-to-day basis.

Data scientists are all different, and most aspects of their responsibilities cannot be generalized as they are donned with multiple hats. Charlie is an example that we will consider a typical data scientist.
7 AM Wake Up – An Early Riser
Charlie’s day starts with the first cup of coffee, the start of many. Checks his emails for any alerts on the code that has been in operation through the night and reacts if necessary.
8 AM Head to Work – Commute
When working on complex data science projects, Charlie is intensely thinking about which machine learning approach would work best for his dataset on his commute to the office. On other days when the data product has already been built and the team is working on code polishing or other temporal activities, Charlie spends his commute time listening to some interesting data science podcasts or classic music.
9 AM Arrive at Work
Grab a cup of coffee and head to the desk. A busy day starts. Last week Charlie’s data science team released a new recommender engine. Charlie monitor’s the outcome of this recommender engine to see if there have been no surprises or critical issues during the night that need dealing with. Charlie then checks the infrastructure health and data pipeline to ensure everything is working as expected.
11 AM Sprints and Stand-up Meetings
Yesterday, Charlie has been working on optimizing and tuning the parameters of a random forest machine learning model. Today, he plans to evaluate the accuracy and variations in predictions of all the tuned parameters. Charlie and his team hold meetings with different cross-functional members. They have meetings with various stakeholders, the project managers, marketing, and sales, and mention what they’re working on and what they plan to work on next. The stakeholders brief the data scientists more in detail about the users and share the customer feedback reviews. This helps Charlie and his team understand their goals and how the data can be leveraged to achieve these goals.
There is another meeting that Charlie attends with peer data scientists and data analysts where his team presents the actual details of the project, shares the code and visualizations with each other, and discusses the progress. These meetings are typical task trackers to ensure that everyone in the data science team is on the same page and to ensure that there are no blockers. Charlie and his team use Jira task management platform to organize tasks to display sprints and group the tasks based on where they are in the data science process.
1 PM Lunch
Lunch is sometimes delayed not because Charlie is not hungry but because sometimes he gets so busy and engrossed in the code that he has his lunch only after he feels that he has made some progress towards analysis.
2 PM – 5 PM Code, Code, and Code
Developing a machine learning model requires several days, weeks, or months and there is a step-by-step process every data scientist follows. This is the time when actual requirements gathering, data preparation, exploratory data analysis, feature engineering, and model building takes place. Some days Charlie is building data cleaning or plumbing services using various data scientist tools, other days he could be doing some academic style-research and coding in Python (a widely-used programming language in the domain of data science) to implement a machine learning algorithm. He could also be performing analysis in the Jupyter notebook using SciKit learn or firing up PyCharm to code up a class that implements a machine learning model or interfaces with the database.
He could be using Spark MLlib library to churn machine learning models or do k-means clustering, or he could be prototyping in R using ML packages or could be creating beautiful data visualizations using Tableau or Qlikview to communicate the insights to stakeholders or he could be using Apache Hive to pull data or could be creating summaries by pulling data in an excel. Charlie also helps his team members to improve their machine learning models by testing the current model on real data and identifying any false negatives. He also creates new training examples to fix problems if any.
6 PM Code Revie
Having coded all day long, it’s time to let your peers know about the changes you have committed. Code reviews usually happen over conference calls or through in-person meetings. Charlie takes the help of other data scientists in his team when he is stuck with a code snippet and also makes it a point to explain the code to his peers so he knows his code better. The collaboration of new ideas and brainstorming happens in these meetings.
7 PM – End of a Hectic Day….Home Time!
Charlie heads back home but if there is any data science or tech event happening in his company he makes it a point to attend that so that he can learn new things from brilliant tech minds. Charlie likes to unwind during his evening by researching some latest data science trends and technologies to keep himself updated.
This is what a typical day in the life of a data scientist looks like but as already mentioned this varies from project to project, company to company, and person to person. There are many data science companies and hundreds of data scientists but the data science process and the tasks a data scientist will be involved in remain the same.
A day in the life of a data scientist is similar to the life of a writer who is always immersed in a deep state of concentration. A typical day in the life of a data scientist is never boring or dull, instead, it is full of challenges and opportunities to learn new things and solve new business problems.
There’s no question that learning data science can completely transform your career prospects. Data science skills are in-demand, with India alone likely to see a 62% increase in data science job openings. And the data science industry is also popular for its high salaries – the average data scientist salary is 10 lakhs per annum. If you like the sound of Charlie’s day and the perks a data scientist job entails, enroll in Springboard’s comprehensive, 1:1 mentor-led data science online program to become a qualified data scientist in 6 months with a job guarantee. If we can help you become a data scientist, it’ll be worth it.
And one more recap from Mozilla data scientist, Ryan:
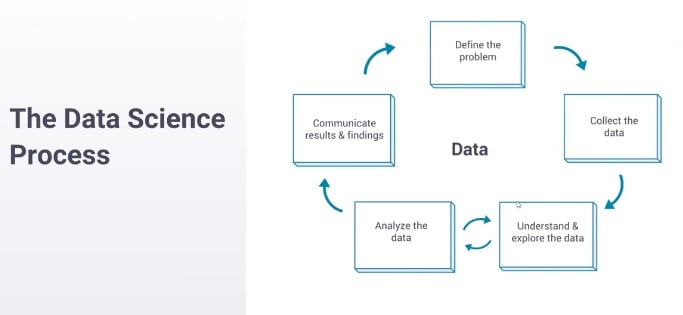
You start by defining a problem. You start with something that you want to understand better or a question that you want to answer. You move on to collecting data to answer that question. Then you enter this loop at the bottom here, where you oscillate between understanding the data and exploring the data—so, making some assertion about the data and then analyzing whether that’s true and whether you really do understand, and then going back and forth until you feel like you completely understand what the data is saying. Then you move on to communicating your results—and this is where you take what you’ve learned and you make it something that the company can use.
With that in mind, Ryan detailed the type of project a data scientist at Mozilla might work on.
Related Read: 6 Complete Data Science Projects, Plus Tips to Build Your Own
We have this feature called container tabs. It allows you to isolate personas when you’re online so you can have your work Gmail and your personal Gmail sitting next to each other and they don’t know that they’re both in the same browser, for example. So, I’ll take you through how we would actually analyze whether this change is useful. This is a pretty canonical data science question, at least at a tech company where we’re trying to run A/B experiments and figure out what features are good for our users.
1. Understand the problem: We start by understanding the problem, and this usually looks like sitting down with the person who owns this feature, who built this feature, and asking them: what does it do, what are you concerned about, how could this break the user experience, and what do you think this is going to do for your users? How would you characterize success, what does a happy user look like, and how do we win? So, we sit down in this meeting and I’m trying to build an understanding of what this feature is and then how we’re going to measure it.
2. Collecting data: Once I understand why they’re coming to me—are they trying to figure out if this feature is good? Are they trying to figure out if this feature’s good enough to launch (which is kind of a different question)? Are they trying to figure out if it causes pages to crash—may be a more narrow question? Once I understand what they’re trying to figure out, I can help them collect data.
So in this example, they want to answer some questions about causation. They want to know if launching this feature is good for the user, produces more users, produces happier users, or something like that. And because they’re trying to establish some type of causation like that, we need to run an experiment, which is different than—a lot of questions are just descriptive, right? So they’re asking questions like: how many users do we have in Germany? That’s something that we can answer quickly without running an experiment. We can just query the database and figure out the answer. This needs more. We need to separate users into groups, apply treatment, and understand what the actual effect is.
Something that we deal with at Mozilla that’s maybe [unique] to our process is that we spend a lot of time working on maintaining user privacy. We spend a lot of time thinking about: what’s the minimum amount of data that we can collect to be able to make sure that this is actually good for our users? This produces a bunch of data science questions that are difficult to answer. Can we fuzz the data to make sure we never know what one person did or can we just ask for, maybe, counts of websites instead of which websites? This adds a lot of complexity to the data collection process.
3. Understanding the data: To summarize, we understand the problem, we’ve decided that we’re going to run an experiment, we launch an experiment, and we collect some data. Moving on, once we have some data, we need to understand it. This process, like I said before, looks a lot like an oscillation.
So, we start off by making some assertions about the data: OK, there should be like a million rows in this data set. And then you look and you see there’s 15 million and you’re like, that’s not what I expected there to be. There’s an assertion there and there’s an analysis to figure out whether your assertion’s right and you just go through these frequently. OK, there’s 15 million instead of 1 million; what’s going on there? Oh, there are more users enrolled than I thought there would be because there are more people in Germany than I thought there would be. And you just keep oscillating through this until you come to a pretty complete understanding of what the data say.
So, you say something along the lines of why do these users leave, why is this metric so noisy? You say, oh there are outliers. The outliers are because of bots, so we can remove that. Finally, you have a complete understanding of the story. And if somebody asks you a question about the data, you can say: yeah, no, that’s not really a problem.
4. Communicating the results: Once you understand the data, you need to work on communicating the results so that other people can act on them. So this can be, you know, going into every meeting that people have about this feature and explaining why it’s good or bad. Usually, it’s more effective to produce some reports and make a launch/no launch assertion. So you say: this is good because of these reasons, this is what we observed, this is how we measured.
Something that I’ve been working on recently is building these reports effectively. And one of the things that I’ve been working on is building archival-quality reports, reports that don’t look different 10 years from now, which is unusually difficult to do when you’re working with something that’s on the internet, right? Things move, things break, things change. But the goal here is to be able to take what you’ve learned, put it down on paper so it distributes to a bunch of different people, so they can read and understand and change the way that they make decisions, and document this so well that in a few years we can reverse the decision that you suggested if everything’s changed—that’s, like, the gold standard of giving a great experiment report.
After talking through the life of an example project, Ryan discussed some of the tools he might use to accomplish that work.
You’re going to need some programming language—Python is what I use right now because it’s supported by our team. We have really good support for PySpark, which is the Python interface for Spark. Previously I’ve used R and I’ve been very happy with it. I use Jupyter notebooks a lot for exploration, but when I’m trying to communicate results or distill my knowledge I usually do it in Markdown or GDocs. And if it’s in Markdown, then it’s on GitHub, stored in Git.
These are some of the tools you’ll run into. These I think are pretty standard and useful across the industry. There are definitely more niche tools and the toolchains for data scientists are very, very varied because there are so many different types of jobs.
But what does a single day in the life of a data scientist like Ryan look like? He explains:
My time’s roughly split evenly between analysis, meetings, and review.
The analysis is me actually doing computation, writing queries, and trying to gauge something about the universe that isn’t understood right now.
Meetings and scoping analyses—these are understanding the problem and communicating my results out. I spend a lot of time in meetings trying to draw value from the analyses that I’ve done.
And then separately I spend a lot of time reviewing and answering questions for other folks. This can be something as simple as writing a quick query for a question that doesn’t need a lot of work or reviewing some more junior analyst’s analysis, or maybe even some PM’s analysis.
This changes with seniority. I’m a fairly senior now. When I started, I was doing a lot more analysis, a lot more drawing numbers, and a lot more building reports. As I’ve moved up I’ve produced more reviews. More senior people do a lot of reviews; mid-levels a lot of meetings, communication, and making sure the processes work. And then a lot of analysis for more junior members.
For more from Ryan, watch the full webinar.

Here’s what a typical day looks like in the life of a Walmart Data Scientist at Walmart Labs –

Here’s what a typical day looks like in the life of a Zeotap Data Scientist –

Since you’re here…
Thinking about a career in data science? Enroll in our Data Science Bootcamp, and we’ll get you hired in 6 months. If you’re just getting started, take a peek at our foundational Data Science Course, and don’t forget to peep our student reviews. The data’s on our side.
![87 Data Science Interview Questions [2022 Prep Guide]](https://www.springboard.com/blog/wp-content/uploads/2018/11/87-data-science-interview-questions-2022-prep-guide-380x235.png)

