My experience with Springboard’s Data Science Career Track

This post originally appeared on Medium.
Ever since I completed Springboard’s Data Science Career Track, I have been receiving messages from people asking me about my experience and trying to gauge if the track would be a good fit for their future career goals.
Therefore, in this post, I shall be describing my four-month journey with DSC. To put it succinctly, it was the most fruitful months I’ve had during my undergraduate life and it made me strongly consider Data Science as a long-term career.
Internship and the Backdoor
During the summer of 2017, I interned with Springboard as a software developer for seven weeks. One of my job perks was access to all of Springboard’s content.
Summer Intern Diaries: Springboard
However, since I was working two jobs, I didn’t really find time to enroll for any course. But casually going through the product piqued my interest. I had never delved into data science but I felt like it was something that I would like to explore.
In the last few days of my internship, I had the opportunity to interact with Parul Gupta, Springboard’s co-founder. I asked her if I could pursue the Data Science Career Track after my internship, once college started. She very generously agreed and gave me a backdoor to the track for 4 months. Pursuing this track, valued at $7500, under the guidance of an industry expert was like once in a lifetime opportunity for me and I was eagerly looking forward to it. I was not disappointed.
Phase 1: The Mentor, Kaggle and TED
I had tried to get my hands dirty with data science before. But I always felt overwhelmed and lost due to the sheer number of skills, tools and libraries you were expected to know. Should I learn Python or R? Do I begin with NumPy or pandas? How is this different from AI courses?
I was extremely relieved when I looked at the curriculum. One of track’s biggest takeaway is its structure. Springboard streamlines the entire learning process for you and gives you suggested study plans to complete the curriculum in 4, 5 and 6 months. Additionally, the technical material is very well interspersed with career coaching advice and practice to help you get a job by the time you graduate.
I was also assigned my mentor; Baran Toppare, a data scientist from Turkey. If there was THE biggest takeaway of this course, it was his mentorship.

Since DSC was primarily based on Python, a language I was familiar with, I didn’t have a very hard time starting with the material. The first parts of the curriculum covered data wrangling (using SQL and Pandas) and data storytelling. For job preparation, I had to update my LinkedIn Profile and set up a new GitHub repository for my projects.
Working on Yammer’s search functionality was one of my first technical projects and I immensely enjoyed working on it. However, the highlight of this phase was something far more significant and made me seriously consider data science as a career.

For my data visualisation project, I narrated the story of TED Talks using a 2012 dataset containing talk transcripts and metadata. Baran was extremely impressed with my project and he encouraged me to publish the dataset and my notebook on Kaggle.
Within a day of publication, I received a ‘bronze’ for my notebook and my dataset was featured and tweeted by Kaggle. As a beginner who was barely a month in, this was extremely exciting for me. However, they cherry on the cake was when the CEO of Kaggle commented this on my notebook.
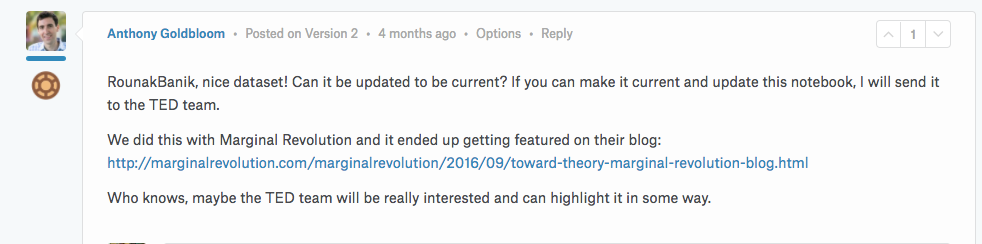
I was over the moon. So, in the following week, I scraped the TED.com website to extract metadata and transcripts for every talk that had ever been published on the platform. With my notebook and dataset updated, Anthony sent my work to the TED Team. I also received a reply from Bruno Giussani, managing director of TED Europe, who said he loved my work and he would definitely share it with his colleagues.
Get To Know Other Data Science Students

George Mendoza
Lead Solutions Manager at Hypergiant

Aaron Pujanandez
Dir. Of Data Science And Analytics at Deep Labs

Isabel Van Zijl
Lead Data Analyst at Kinship
Phase 2: Statistics, SciPy, AMEX and Airbnb
The module that I had the most difficulty with was inferential statistics. And to be honest, if it wasn’t for my mentor, I would have given up at this point. However, Baran really shone with this one.
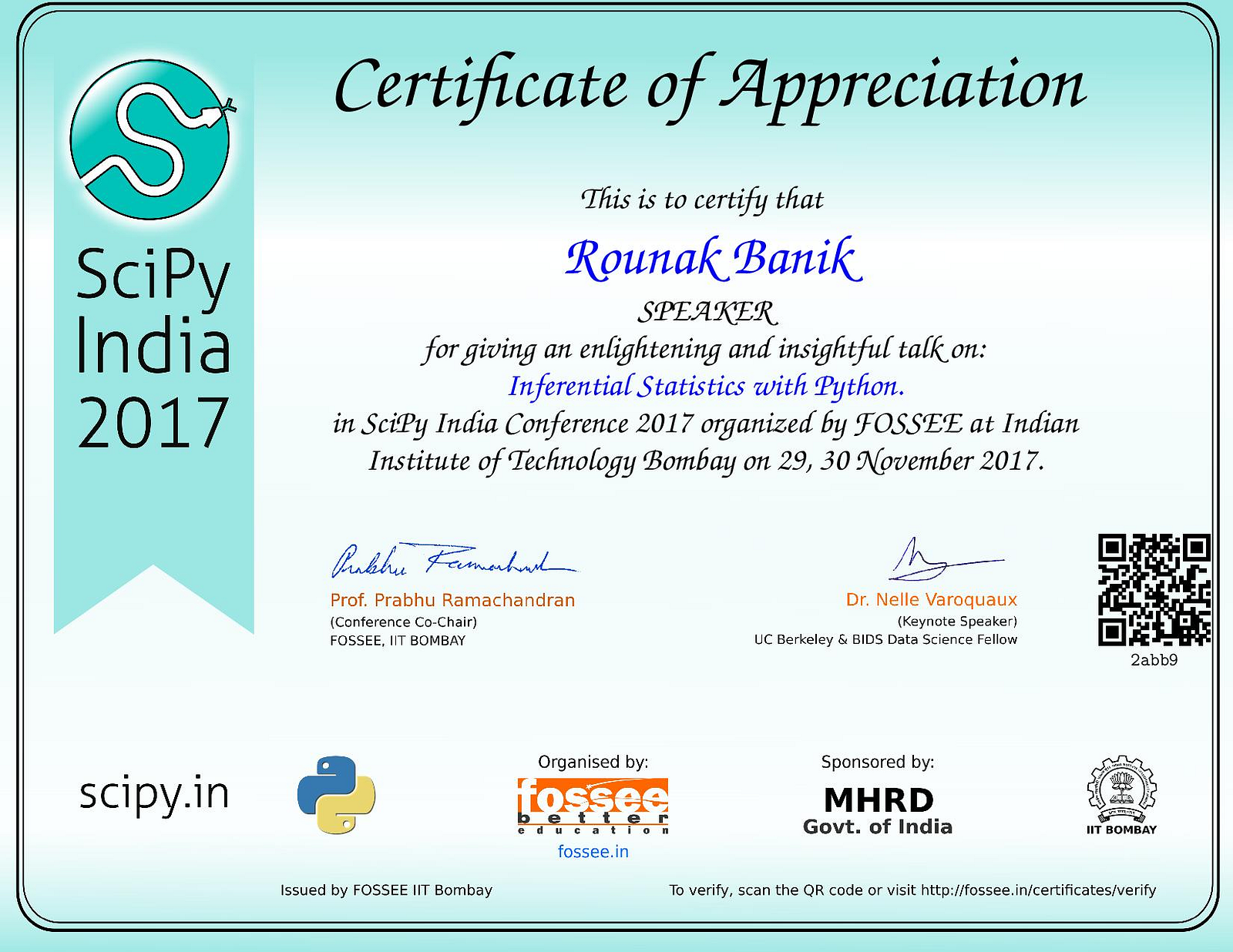
His advice and suggestions on my projects were some of the very best. He also linked me to a treasure trove of articles, books, and videos about the subject. Going through this suggested material got me so comfortable with the subject that I ended up writing a series of tutorial notebooks on the subject (with Baran’s guidance) and ended up giving a talk on inferential statistics at the SciPy India Conference at IIT Bombay!
At this point of time, American Express was also organizing a national level data science hackathon where participants had a week to solve a classification problem. When the competition started, I had absolutely no knowledge of machine learning and I didn’t intend on participating.
However, when I mentioned this to Baran in our next call, he strongly encouraged me to take part. He advised me to spend more time on wrangling and feature engineering. For the machine learning part, he asked me to learn a little bit of scikit-learn and read up on Random Forests and XGBoost, stating that the latter was usually used in most winning solutions.
I did exactly that. And although neither of us had expected it, I ended up being ranked 12 in the National Public Leaderboard and received a certificate from AMEX for Outstanding Performance. It was at this point of time that I really started believing that I could be good at this—and I had only Baran and Springboard to thank for it.

Phase 3: Airbnb and informational interviews
Apart from a myriad of technical assignments, Springboard also expects you to complete two capstone projects as part of the curriculum. These projects have to be proposed by the student and is unique to every student. This way, the student gets to know about the amazing variety of problems that can be solved with data and also build something from scratch; right from acquiring data to giving business recommendations.

My first capstone project was on Airbnb New User Bookings, which was based on an archived competition conducted by Airbnb on Kaggle. With my newfound confidence from the AMEX Competition, I was able to complete the machine learning module with relative ease and complete my capstone within a week.
Working with the Airbnb project got me really interested with Airbnb itself and curious about the kind of challenges it faces. Coincidentally, this was also the time I was expected to conduct informational interviews with professional data scientists as part of my job prep.
As luck would have it, Baran personally knew a data scientist from Airbnb and introduced me to him.
I had an hour-long conversation with Chirag Mahapatra and he gave me an invaluable sneak peek into the kind of problems that the Airbnb data team was solving. He told me about the kind of people Airbnb looks for and it really made me wish for an opportunity to work in such an environment in the future. We also ended conversing a little about Bitcoin and blockchain.
My second interview was with Bahar Erar, a research scientist at Amazon (also introduced by Baran). Bahar came from a Ph.D background and gave me a very different perspective of coming into data science (from an academic background). Like Chirag, Bahar gave me an insight into the kind of work Amazon does and also gave me advice on higher education and the prospect of getting jobs in the United States.
Phase 3: Movies, Datacamp and the Kaggle Kernel Award
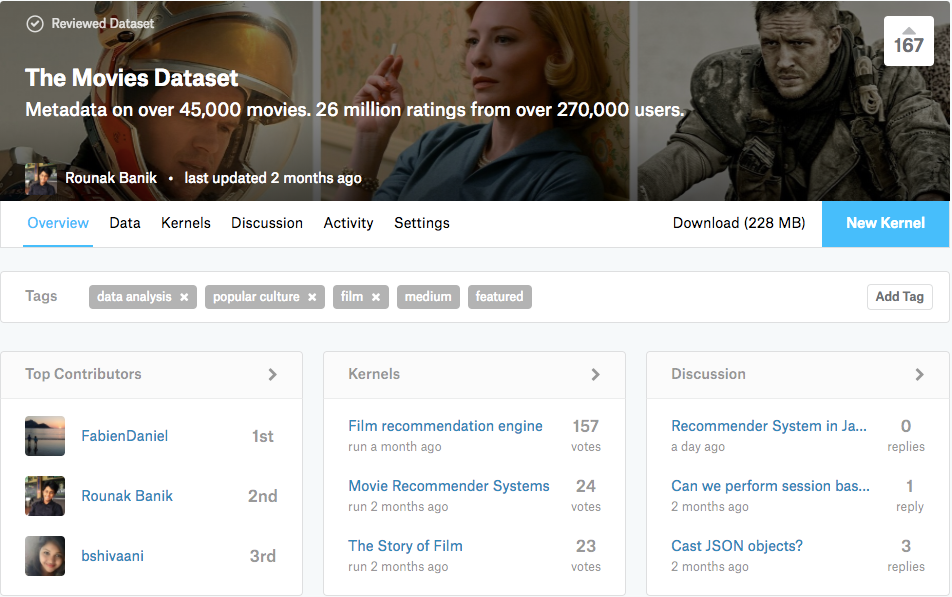
The next phase of the program had me working on my second capstone project, advanced machine learning (time series, recommender systems, etc.) and big data technologies.
Inspired by the success of my TED Project, I decided to do a similar project with movies. For this, I acquired movie metadata from TMDB for over 45,000 movies released between 1874 and 2017. I also uploaded the dataset on Kaggle and it trended on the top for three straight days. It is also the largest movie dataset currently available on Kaggle.
Since my capstone project was required to have a machine learning component, Baran suggested I also work on Movie Recommender Systems. I did exactly that and build three types of recommenders: Simple (an IMDB Top 250 clone), Content-Based, and Collaborative Filters. A portion of my project was also accepted by DataCamp as a tutorial.
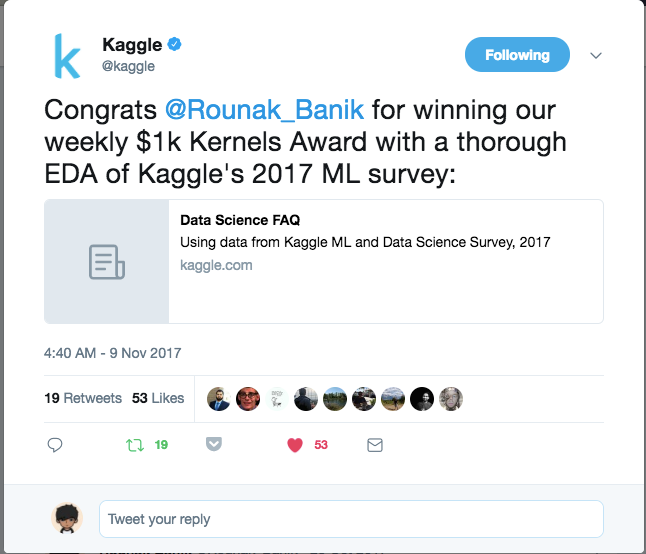
My journey was approaching the end. As luck would have it, I was also independently working on a separate kernel on the state of Data Science and ML on Kaggle. The kernel ended up winning the very first $1000 Kaggle Kernels Award.
Final Phase: Project Walkthroughs, BTP and UpGrad
My experience with the program had been so good that, for my B.Tech Final Project, I proposed a data science problem: Fake News Detection. I begin extensively studying natural language processing at this time.

In my final phase of the program, I was expected to go through a few mock interviews. My project walkthrough interview was with Dipanjan Sarkar. Coincidentally, I had been reading his book to work on my Fake News Detection problem. It was truly a surreal experience to have the author of a book you were reading, reviewing your projects. And I think this encapsulates the true essence of Springboard’s program: an extremely powerful network of people to learn from and connect with.
A few days before graduating, I received an offer from UpGrad to write articles on the topics of Data Science, Software Engineering, and Web Development. I ended up authoring an article on how to start with Data Science which was heavily influenced by my experience with this program.
Get Started in Data Science with Python | UpGrad Blog
Conclusion
To sum up, pursuing Springboard’s Data Science Career Track was one of the most fulfilling and challenging experiences of my life. Although I had taken up this program purely out of intellectual curiosity, by the time I was done, I was certain that I would love to become a Data Scientist someday.
When I was pursuing this program, I didn’t really put in too much work with the job search components since I wasn’t really looking for a job. Therefore, I do not have too much to comment on that. However, I’m sure that with the network I’ve newly built, I’m in a very good position to interview for jobs that are a good fit and I’m passionate about.
In case you’re interested, this is some of the code I’d written as part of DSC:
If you have any questions regarding the track, feel free to drop me a mail at rounakbanik@gmail.com. Thank you for reading!
Since you’re here…Are you a future data scientist? Investigate with our free guide to what a data scientist actually does. When you’re ready to build a CV that will make hiring managers melt, join our Data Science Bootcamp that guarantees a job or your tuition back!


